错误分类
软件程序中,我们可以将错误大致分为外部错误和内部错误两大类。
外部错误是正确编写的程序在运行时产生的错误。它并不是程序本身的 bug,更多是一些外部原因导致的问题,比如请求超时、服务器返回500、内存不足等。
而内部错误是程序里的 bug。比如传参类型错误、读取 undefined 的一个属性等。这类问题跟你选择的开发语言、开发者的编程经验、系统复杂度等因素息息相关,虽然无法避免,但可以通过修改代码来修复它。
对应到 Node.js 程序上,一般遇到以下四类错误:
- 标准的 JavaScript 错误。例如 SyntaxError、RangeError、ReferenceError、TypeError等。
- 由底层操作系触发的系统错误,例如试图打开不存在的文件。
- 用户自定义错误。
- 断言错误。这类错误通常来自 assert 模块。
注:本文中不区分错误和异常,都将其统称为错误。
错误处理
当错误发生后,我们需要第一时间去处理它。针对不同类型的错误,有不同的措施。处理错误的总体原则:
- 及时止损,防止系统级崩溃。
- 详细记录现场,方便分析原因。
外部错误
程序运行过程中,可能会遇到各种外部因素导致的问题,这些问题需要具体问题具体分析。我们没办法保证外部服务提供方的稳定性,但是遇到此类问题时,可以做一些事情,来保证我们的程序不至于直接崩溃。
举个例子,秒杀场景的业务经常会承受非常大的 QPS,在一波瞬间大流量的冲击,后端服务扛不住的话会报 5XX 错误。在后端服务挂掉后,我们可能会去读 redis 等缓存中的数据,用旧数据来兜底。而当 Node.js 应用也挂掉了,还可以在 Nginx 层进行 CDN 降级,给用户输出一个兜底的静态页。
还有些来自后端服务的错误,只需要进行简单的重试就能解决。如果要重试的话,要确定重试的次数,以及重试的间隔。
有人建议在发生错误后直接崩溃掉,防止错误扩散。个人认为其实是不合理的,会降低服务的可用性。我们可以在出现一些严重的错误后,先记录下错误,然后重启进程。在 Node.js 中,未捕获的 JavaScript 异常一直冒泡回到事件循环时,会触发 process.uncaughtException 事件。我们可以在事件回调中做错误上报,然后重启 Node.js 进程。这时,还需要借助 Cluster 来启动多个 Node 进程,保证单进程崩溃重启不会影响整体服务的可用性。实际的生产环境中,使用 PM2 来管理 Node.js 进程是一个更好的选项。
我们永远也无法阻止外部错误,它跟你的业务场景、用户终端等各种不可控的因素相关。但是我们如果做好监控、告警、日志、缓存等工作,可以方便程序员迅速定位/解决问题,从而将损失降至最低。
内部错误
同步场景
对于 JavaScript 错误,我们可以使用 throw 抛出,并用 try catch 来捕获住。
try { |
而且对于 throw 抛出的异常必须要 try catch 包裹,否则 Node.js 进程会直接退出。这种写法可以获取到完整的错误调用堆栈。比如:
fs.js:115 |
众所周知,JS 函数调用会形成一系列的栈帧,为了尽可能的恢复错误发生现场,最好在错误上报时带上堆栈信息。Node.js 中,Error.captureStackTrace() 方法是 v8 引擎暴露出来的,处理错误堆栈信息的 API。
Error.captureStackTrace(targetObject[, constructorOpt])
在 targetObject 中添加一个 .stack 属性。对该属性进行访问时,将以字符串的形式返回 Error.captureStackTrace() 语句被调用时的代码位置信息(即:调用栈历史)。
值得注意的是,它的第二个参数可以用来控制栈帧的终点。在一些底层库中,这个参数可以用来向开发者隐藏内部实现细节。
实际的生产环境中,我们可以使用 nested-error-stacks 这类 npm 包来采集堆栈信息,原理其实也是基于 Error.captureStackTrace()。
这里有个问题是:try catch 代码块是同步的,对于异步 API 发生的错误,它不能捕获到。
比如下列代码:
try { |
错误并不能被捕获住。这个跟 Node.js 的事件循环机制有关,因为异步任务是通过事件队列来实现的,每次从事件队列中取出一个函数来执行时,实际上这个函数是在调用栈的最顶层执行的,如果它抛出了一个异常,也是无法沿着调用栈回溯到这个异步任务的创建者的。
下面介绍下在异步流程中,我们应该怎么处理错误。
异步场景
Node.js 中常见异步场景包括三类:
- Node.js style callback
- Promise
- EventEmitter
大部分异步 API 都遵循错误回调优先的约定,将 Error 作为 callback 的第一个参数来传递,这种风格比较类似函数式编程中的 Continuation-passing style。
fs.readFile(path, 'r', (err, data) => { |
这种写法很容易造成回调地狱。另一方面,对于回调函数中的同步逻辑,我们还需要用 try catch 去单独处理,这导致错误逻辑的处理被分散了两处。Promise 被正式 ES6 标准化后,我们可以用 Promise 的链式调用来处理错误。
new Promise((resolve, reject) => { |
这样,Promise 链上的错误都会在 catch 方法上捕获住。对于没有 catch 的 Promise 异常,会一直冒泡到顶层,在 process.unhandledRejection 事件上被捕获住。
还有一类是 EventEmitter 对象上的错误。它们会被分发到 error 事件上进行处理,比如 Stream 等。我们需要去为每一个流去监听 error 事件,否则会冒泡到process.uncaughtException 事件上去。
异步场景中,还有个问题就是,会丢失异步回调前的错误堆栈。原因还是上文提到的 Node.js 事件循环机制。
const foo = function () { |
输出结果:
Error: some error |
可以看到丢失了 bar 的调用栈。然而在 Node.js 中,异步调用场景还挺多的,有什么办法可以将多个异步调用给串起来,获取到完整的调用链信息呢?答案是有的。Node.js v8+ 上提供了 async_hooks 模块,用来完善异步场景的监控。
async_hooks
async_hooks 提供了一些 API 用于跟踪 Node.js 中的异步资源的生命周期。有几个概念:
- 每个异步函数的作用域,我们称之为 async scope。
- 每一个 async scope 中都有一个 asyncId, 用来标记当前作用域。相同 async scope 的 asyncId 也相同。每个异步资源在创建时 asyncId 全量递增的。
- 每一个 async scope 中都有一个 triggerAsyncId 表示当前函数是由哪个 async scope 触发生成的。
- 通过 asyncId 和 triggerAsyncId,我们可以获取到异步资源的调用链。
- async_hooks.createHooks 函数可以用来给每个异步资源添加 init/before/after/destory 等生命周期钩子函数。
console.log('global.asyncId:', async_hooks.executionAsyncId()); // global.asyncId: 1 |
回调函数中的 triggerAsyncId 为 1,它等于 global scope 上的 asyncId。这样就可以拿到多个异步调用的调用链。
国内的赵坤大神写过一个 koa 日志中间件 koa-await-breakpoint,用于实现在每个 await 执行的语句前后进行自动打点工作。
// On top of the main file |
每个请求到来时,生成一个 requestId 挂载到 ctx 上,通过 requestId 将日志串起来。核心原理是 hack 了模块的 require 方法(重载 Module.prototype._compile),用 esprima 将模块代码转成 AST,找到其中的 awaitExpression 节点,对其用日志函数包裹后重新插入到 AST,最后用 escodegen 将 AST 生成代码。其中还用到了 async_hooks,在日志函数中,基于 async_hooks 的 init 钩子中将异步调用关系存储到一个 Map 中,最终实现函数调用链的自动日志打点。
不过,使用 async_hooks 在目前有较严重的性能损耗。建议生产环境慎用。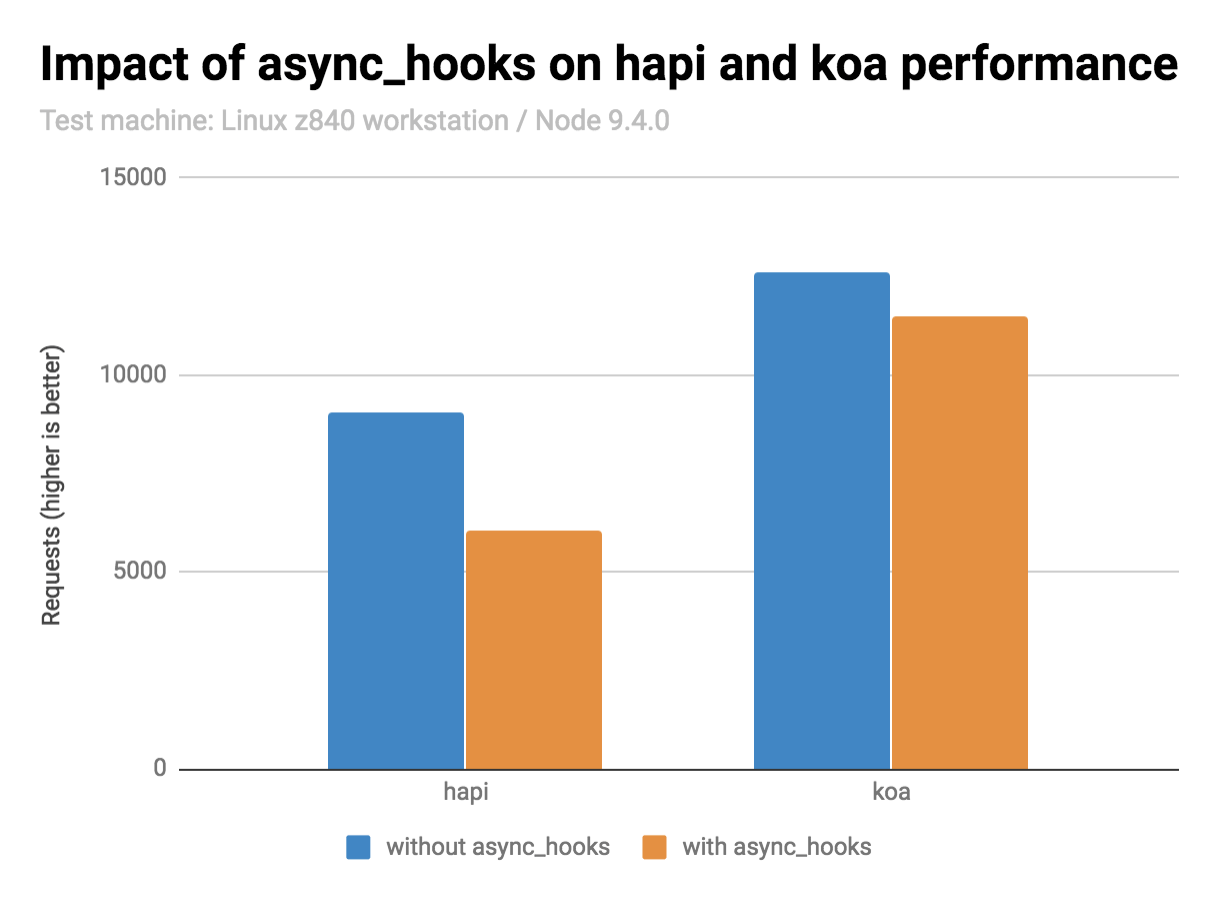
总结
错误可分为外部错误和内部错误两类。对外部错误的处理主要考验系统架构的设计,只有系统设计的足够健壮,才能够抵御各种外部挑战,并损失降到最低。对于内部错误,本文分别讨论了同步和异步两种场景,介绍了 Error.captureStackTrace()、async_hooks 等 API 在收集错误堆栈、异步调用链上的用途,并结合 koa-await-breakpoint 源码,解释了 Node.js 自动化打点的核心原理。
参考链接:
[1] 胡子大哈. 深入理解 JavaScript Errors 和 Stack Traces. https://zhuanlan.zhihu.com/p/25338849
[2] Chuan’s blog. 关于 Error.captureStackTrace. http://blog.shaochuancs.com/about-error-capturestacktrace
[3] joyent. Error Handling in Node.js. https://www.joyent.com/node-js/production/design/errors
[4] 王子亭. Node.js 错误处理实践. https://jysperm.me/2016/10/nodejs-error-handling
[5] 张佃鹏. 学习使用 Node.js 中 async-hooks 模块. https://zhuanlan.zhihu.com/p/53036228
[6] bmeurer. https://github.com/bmeurer/async-hooks-performance-impact
[7] http://nodejs.cn/api/errors.html#errors_errors